
澳门永利龙虎斗[[438061]]澳门永利龙虎斗
数据分析是对数据进行收受、调遣和可视化的过程,用来发掘对业务决策有用的洞见。
在当年的十年中,越来越多的数据被汇集,客户但愿从数据中取得更有价值的洞见。他们还但愿能在最短的时天职(以至及时地)取得这种洞见。他们但愿有更多的临时查询以便修起更多的业务问题。为了修起这些问题,客户需要更强项、更高效的系统。
批处理频繁触及查询广大的冷数据。在批处理中,可能需要几个小时才气取得业务问题的谜底。举例,你可能会使用批处理在月底生成账单阐述。
及时的流处理频繁触及查询少许的热数据,只需要很短的时分就不错得到谜底。举例,基于MapReduce的系统(如Hadoop)便是维握批处理功课类型的平台。数据仓库是维握查询引擎类型的平台。
7月27日13时许,若羌县公安局接敦煌市公安局转警称,一自驾车队于22日自敦煌市出发,未经批准穿越若羌境内国家级野骆驼自然保护区,26日1车4人失联。经搜救,于27日发现失联车辆,3人已无生命体征,1人失踪。车队其余人员已安全返回敦煌市。
流数据处理需要收受数据序列,并凭据每条数据纪录进行增量更新。频繁,它们收受连气儿产生的数据流,如计量数据、监控数据、审计日记、调试日记、网站点击流以及开荒、东说念主员和商品的位置追踪事件。
图13-6展示了使用AWS云时期栈处理、调遣并可视化数据的数据湖活水线。
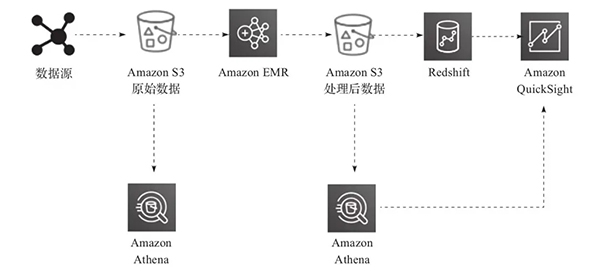
▲图13-6 使用数据湖ETL活水线处理数据

在这里,ETL活水线使用Amazon Athena对存储在Amazon S3中的数据进行临时查询。从各式数据源(举例,Web期骗就业器)收受的数据会生成日记文献,并握久保存在S3。然后,这些文献将被Amazon Elastic MapReduce(EMR)调遣和清洗成产生洞见所需的款式并加载到Amazon S3。
用COPY大呼将这些调遣后的文献加载到Amazon Redshift,并使用Amazon QuickSight进行可视化。使用Amazon Athena,你不错在数据存储时凯旋从Amazon S3中查询,也不错在数据调遣后查询(从团聚后的数据集)。你不错在Amazon QuickSight中对数据进行可视化,也不错在不篡改现存数据经过的情况下猖厥查询这些文献。
以下是一些最流行的不错匡助你对海量数据进行调遣和处理的数据处理时期:
01 Apache Hadoop
Apache Hadoop使用溜达式处理架构,将任务分发到就业器集群上进行处理。分发到集群就业器上的每一项任务都不错在职意一台就业器上运行或再走运行。集群就业器频繁使用HDFS将数据存储到腹地进行处理。
沙巴轮盘体育彩票 线上在Hadoop框架中,Hadoop将大的功课分割成闹翻的任务,并行处理。它能在数目广阔的Hadoop集群中杀青大鸿沟的伸缩性。它还联想了容错功能,每个使命节点都会如期向主节点阐述我方的景色,主节点不错将使命负载从莫得积极反应的集群再行分派出去。
博彩游戏介绍Hadoop最常用的框架有Hive、Presto、Pig和Spark。
02 Apache Spark
Apache Spark是一个内存处理框架。Apache Spark是一个大鸿沟并行处理系统,它有不同的奉行器,不错将Spark功课拆分,并行奉行任务。为了提升着业的并行度,不错在集群中加多节点。Spark维握批处理、交互式和流式数据源。
半场盘口Spark在功课奉行过程中的系数阶段都使用有向无环图(Directed Acyclic Graph,DAG)。DAG不错追踪功课过程中数据的调遣或数据维握情况,并将DataFrames存储在内存中,有用地最小化I/O。Spark还具有分区感知功能,以幸免麇集密集型的数据改选。
03 Hadoop用户体验Hadoop用户体验(Hadoop User Experience,HUE)使你大要通过基于浏览器的用户界面而不是大呼行在集群上进行查询并运行剧本。
HUE在用户界面中提供了最常见的Hadoop组件。它不错基于浏览器检验和追踪Hadoop操作。多个用户不错登录HUE的家数拜访集群,管制员不错手动或通过LDAP、PAM、SPNEGO、OpenID、OAuth和SAML2认证管制拜访。HUE允许你及时检验日记,并提供一个元存储管制器来操作Hive元存储内容。
04 Pig
Pig频繁用于处理广大的原始数据,然后再以结构化花样(SQL表)存储。Pig适用于ETL操作,如数据考证、数据加载、数据调遣,以及以多种花样组合来自多个开头的数据。除了ETL,Pig还维握相关操作,如嵌套数据、迷惑和分组。
Pig剧本不错使用非结构化和半结构化数据(如Web就业器日记或点击流日记)当作输入。比拟之下,Hive老是条目输入数据舒服一定模式。Pig的Latin剧本包含对于如何过滤、分组和迷惑数据的教唆,但Pig并不计算成为一种查询说话。Hive更符合查询数据。Pig剧本凭据Pig Latin说话的教唆,欧博会员官网编译并运行以调遣数据。
05 Hive
Hive是一个开源的数据仓库和查询包,运行在Hadoop集群之上。SQL是一项非通常见的技巧,它不错匡助团队猖厥过渡到大数据宇宙。
Hive使用了一种访佛于SQL的说话,叫作Hive Query说话(Hive Query Language,HQL),这使得在Hadoop系统中查询和处理数据变得相配容易。Hive抽象了用Java等编码说话编写方法来奉行分析功课的复杂性。
06 PrestoPresto是一个访佛Hive的查询引擎,但它的速率更快。它维握ANSI SQL圭臬,该圭臬很容易学习,亦然最流行的技巧集。Presto维握复杂的查询、迷惑和团聚功能。
与Hive或MapReduce不同,Presto在内存中奉行查询,减少了延长,提升了查询性能。在遴荐Presto的就业器容量时需要防卫,因为它需要有满盈的内存。内存溢出时,Presto功课将再行启动。
07 HBase
HBase是当作开源Hadoop样貌标一部分开发的NoSQL数据库。HBase运行在HDFS上,为Hadoop生态系统提供非相关型数据库。HBase有助于将广大数据压缩并以列式花样存储。同期,它还提供了快速查找功能,因为其中很大一部分数据被缓存在内存中,集群实例存储也同期在使用。
08 Apache ZeppelinApache Zeppelin是一个建树在Hadoop系统之上的用于数据分析的基于Web的裁剪器,又被称为Zeppelin Notebook。它的后台说话使用了讲明器的主见,允许任何说话接入Zeppelin。Apache Zeppelin包括一些基本的图表和透视图。它相配活泼,任何说话后台的任何输出恶果都不错被识别和可视化。
皇冠c盘和b盘的区别 09 GangliaGanglia是一个Hadoop集群监控器用。关联词,你需要在启动时在集群上装配Ganglia。Ganglia UI运行在主节点上,你不错通过SSH拜访主节点。Ganglia是一个开源样貌,旨在监控集群而不影响其性能。Ganglia不错匡助查验集群中各个就业器的性能以及集群合座的性能。
皇冠信用盘搭建 10 JupyterHubJupyterHub是一个多用户的Jupyter Notebook。Jupyter Notebook是数据科学家进行数据工程和ML的最流行的器用之一。JupyterHub就业器为每个用户提供基于Web的Jupyter Notebook IDE。多个用户不错同期使用他们的Jupyter Notebook来编写和奉行代码,从而进行探索性数据分析。
皇冠信用盘登3代理 11 Amazon Athena
Amazon Athena是一个交互式查询就业,它使用圭臬ANSI SQL语法在Amazon S3对象存储上运行查询。Amazon Athena建树在Presto之上,并膨胀了当作托管就业的临时查询功能。Amazon Athena元数据存储与Hive元数据存储的使命方式疏导,因此你不错在Amazon Athena中使用与Hive元数据存储疏导的DDL语句。
Athena是一个无就业器的托管就业,这意味着系数的基础设施和软件运维都由AWS崇敬,你不错凯旋在Athena的基于Web的裁剪器中奉行查询。
12 Amazon Elastic MapReduceAmazon Elastic MapReduce(EMR)骨子上是云上的Hadoop。你不错使用EMR来推崇Hadoop框架与AWS云的强项功能。EMR维握系数最流行的开源框架,包括Apache Spark、Hive、Pig、Presto、Impala、HBase等。
EMR提供了解耦的谋略和存储,这意味着不消让大型的Hadoop集群握续运转,你不错奉行数据调遣并将恶果加载到握久化的Amazon S3存储中,然后关闭就业器。EMR提供了自动伸缩功能,为你勤俭了装配和更新就业器的各式软件的管制支出。
13 AWS GlueAWS Glue是一个托管的ETL就业,它有助于杀青数据处理、登记和机器学习调遣以查找不异纪录。AWS Glue数据目次与Hive数据目次兼容,并在各式数据源(包括相关型数据库、NoSQL和文献)间提供聚首的元数据存储库。
AWS Glue建树在Spark集群之上,并将ETL当作一项托管就业提供。AWS Glue可为常见的用例生成PySpark和Scala代码,因此不需要重新运转编写ETL代码。
Glue功课授权功能可处理功课中的任何误差,并提供日记以了解底层权限或数据花样问题。Glue提供了使命流,通过粗浅的拖放功能匡助你建树自动化的数据活水线。
皇冠hg86a
小结数据分析和处理是一个广阔的主题,值得单独写一册书。本文详尽地先容了数据处理的流行器用。还有更多的很是和开源器用可供遴荐。
对于作者:所罗伯·斯里瓦斯塔瓦(Saurabh Shrivastava)是一位时期教唆者、作者、发明家和公开演说家,在IT行业领有卓绝16年的使命劝诫。他现在在Amazon Web Services(AWS)担任处置决议架构师团队崇敬东说念主,匡助大家谈论团合资伴和企业客户伸开云谋略之旅。他还牵头了大家时期伙伴的兼并,何况领有云平台自动化鸿沟的专利。
内拉贾利·斯里瓦斯塔夫(Neelanjali Srivastav)是一位时期教唆者、敏捷讲授和云谋略从业者,在软件行业领有卓绝14年的劝诫。她领有昌迪加尔旁遮普大学生物信息学和信息时期专科的学士和硕士学位。
本文摘编自《处置决议架构师修皆之说念》,经出书方授权发布。(ISBN:9787111694441)